

Intégrer des assistants vocaux dans des haut-parleurs portables et des casques intelligents
Avec la contribution de Rédacteurs nord-américains de DigiKey
2019-09-26
Les assistants virtuels comme Alexa d'Amazon, Siri d'Apple, Cortana de Microsoft et l'Assistant Google entraînent la création de dispositifs intelligents à reconnaissance vocale, qu'il s'agisse de casques Bluetooth associés à des smartphones et à d'autres dispositifs mobiles, ou de haut-parleurs intelligents pour la domotique et la bureautique, ou encore de produits électroniques grand public, comme les téléviseurs. Alors que les services à reconnaissance vocale sont de plus en plus utilisés pour contrôler des fonctions telles qu'écouter de la musique, passer des appels et faire fonctionner des capteurs biométriques, les concepteurs rencontrent des difficultés pour identifier, capturer et transmettre des commandes vocales sans fil dans des environnements souvent parasités par du bruit acoustique et électrique.
Cela requiert des techniques fiables d'annulation du bruit et une interface sans fil efficace, le tout dans une seule solution que les développeurs peuvent tester et appliquer rapidement pour gagner du temps et faire des économies.
Cet article présente plusieurs solutions de capture vocale de Cirrus Logic, XMOS et Qualcomm, développées dans le but d'aider les concepteurs à se lancer rapidement dans la création de la future génération de casques et de dispositifs mobiles à reconnaissance vocale.
Solution de capture vocale
Alors que des entreprises comme Apple et Microsoft ont commencé à implémenter leurs solutions dans des smartphones et des ordinateurs, Amazon a lancé Alexa avec le haut-parleur intelligent Echo, puis a commencé à déployer son utilisation dans davantage de dispositifs.
Cependant, le haut-parleur Echo contient sept microphones, ce qui est bien trop pour un petit dispositif portable pour lequel l'espace, les coûts et la puissance sont essentiels. Cela dit, les fabricants de puces comme Cirrus Logic se lancent avec des solutions de conception plus simples pour permettre aux concepteurs d'intégrer Alexa dans divers dispositifs intelligents et autres systèmes audio de différentes tailles.
C'est par exemple le cas des applications domestiques intelligentes qui utilisent le service vocal Alexa (AVS) dans les systèmes d'éclairage et les appareils électroménagers à commande vocale, les haut-parleurs mains libres et les haut-parleurs en réseau. Des solutions de capture vocale sont alors nécessaires pour améliorer l'expérience utilisateur en supprimant le bruit et d'autres interférences provenant du monde réel, pour des interactions vocales plus précises et plus fiables.
L'implémentation d'un assistant vocal requiert l'utilisation d'un mot déclencheur très précis et l'interprétation d'une commande dans des environnements bruyants et pendant la lecture de musique. L'annulation de l'écho est également essentielle pour atteindre une expérience utilisateur de qualité ; elle permet à l'utilisateur d'interrompre la lecture d'une musique forte et les réponses d'Alexa pour formuler de nouvelles demandes et obtenir des réponses précises.
Le kit de développement de capture vocale 598-2471-KIT de Cirrus Logic constitue un bon point de départ pour tester des conceptions avec le service vocal Alexa (AVS). Ce kit a pour objectif d'intégrer la fonctionnalité Alexa dans des dispositifs audio compacts avec des composants matériels et logiciels de traitement de son modulé (Figure 1). Il est basé sur une plateforme Raspberry Pi 3 et inclut une carte de référence qui contient un codec intelligent CS47L24-CWZR de Cirrus Logic, des microphones MEMS numériques et des algorithmes SoundClear® pour la commande vocale, la suppression du bruit et l'annulation de l'écho.
 Figure 1 : Le kit de développement de capture vocale 598-2471-KIT de Cirrus Logic pour les dispositifs compatibles avec le service vocal Alexa permet de connecter une carte de capture vocale (en haut à droite) à un Raspberry Pi 3 (en haut à gauche) à l'aide d'un câble ou en la fixant sur le Raspberry Pi 3. (Source de l'image : Cirrus Logic)
Figure 1 : Le kit de développement de capture vocale 598-2471-KIT de Cirrus Logic pour les dispositifs compatibles avec le service vocal Alexa permet de connecter une carte de capture vocale (en haut à droite) à un Raspberry Pi 3 (en haut à gauche) à l'aide d'un câble ou en la fixant sur le Raspberry Pi 3. (Source de l'image : Cirrus Logic)
Modules de capture vocale
Le processus de capture vocale commence avec le processeur vocal CS47L24 qui combine un DSP double cœur de 300 MMAC et un codec de concentrateur audio pour une utilisation avec différents blocs de traitement audio écoénergétiques à fonction fixe (Figure 2). Les cœurs DSP programmables prennent en charge une gamme de fonctionnalités de traitement audio avancées, comme la suppression du bruit multi-micros, l'annulation de l'écho acoustique (AEC) et la reconnaissance vocale.
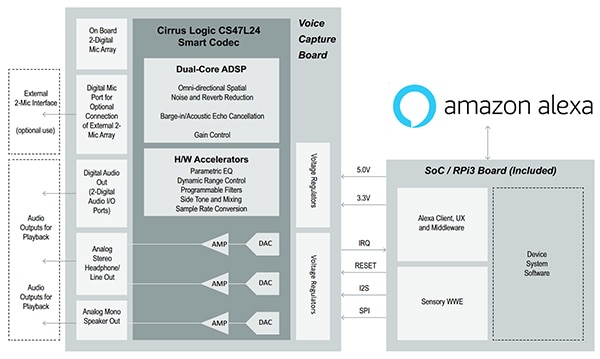 Figure 2 : La capture vocale avec le kit commence avec le processeur vocal CS47L24 qui combine un DSP double cœur de 300 MMAC et un codec de concentrateur audio pour une utilisation avec différents blocs de traitement audio écoénergétiques à fonction fixe. (Source de l'image : Cirrus Logic)
Figure 2 : La capture vocale avec le kit commence avec le processeur vocal CS47L24 qui combine un DSP double cœur de 300 MMAC et un codec de concentrateur audio pour une utilisation avec différents blocs de traitement audio écoénergétiques à fonction fixe. (Source de l'image : Cirrus Logic)
Le codec intelligent CS47L24 utilise un convertisseur numérique-analogique (CNA) intégré avec un circuit d'attaque de haut-parleur mono de 2 W pour favoriser une lecture audio haute fidélité. Il prend en charge une détection du taux d'échantillonnage automatique, ce qui permet de transférer des appels à large bande et à bande étroite. Trois interfaces audio numériques sont fournies sur le processeur CS47L24, chacune prenant en charge une gamme de taux d'échantillonnage audio et de formats d'interface série standard.
Le processeur CS47L24 est alimenté par des sources externes de 1,8 V et 1,2 V. Son architecture de circuit d'attaque de sortie, d'alimentation et de cadencement est entièrement conçue pour une basse consommation en modes de reconnaissance vocale, musique et veille. Le processeur CS47L24 offre également une entrée MICVDD distincte pour le fonctionnement du microphone au-dessus de 1,8 V.
Le circuit intégré de microphones MEMS numériques et les algorithmes SoundClear associés pour la commande vocale, la suppression du bruit et l'annulation de l'écho offrent une audio haute qualité en entrée tout en réduisant la consommation énergétique du microphone. Le circuit intégré prend en charge deux modes opérationnels : le mode basse consommation, qui convient à la détection d'activité vocale en continu, et le mode hautes performances, qui est optimisé pour les enregistrements haute fidélité. Le mode est déterminé par la fréquence d'horloge appliquée.
Le microphone intègre un convertisseur analogique-numérique (CAN) pour produire un flux de données à un bit avec un codage à modulation d'impulsion-densité (PDM) et pour connecter efficacement plusieurs microphones dans des configurations en stéréo et en réseau. Pour les concepteurs, il est important de s'intéresser aux circuits intégrés à plusieurs microphones, car ils peuvent être optimisés pour offrir une réduction du bruit agressif et une annulation de l'écho grâce à des techniques de formation de faisceaux permettant d'obtenir une communication en duplex intégral et une capture audio optimales.
Le microphone MEMS doit également capter une plage dynamique étendue (100 décibels [dB] est un bon point de départ) entre le seuil de bruit et le point de surcharge acoustique. Cela permet de réaliser des enregistrements audio haute fidélité aussi bien dans des environnements calmes que dans des environnements bruyants. Par exemple, cela permet d'enregistrer du contenu à faible niveau sonore (comme de la musique classique ou une voix) sans sifflement de fond. En même temps, cela garantit que les sons très forts, comme les concerts de rock ou le bruit du vent, ne provoquent pas de distorsion au niveau du microphone.
Pour tirer pleinement parti du matériel, les algorithmes SoundClear éliminent le bruit grâce à des fonctionnalités de traitement, comme la suppression du bruit, la fonction Enhance™ d'amélioration de la reconnaissance vocale automatique (ASR) et l'annulation de l'écho.
Capturer la voix en champ lointain
Le kit de développement stéréo XK-VF3500-L33-AVS VocalFusion™ de XMOS pour le service vocal Alexa d'Amazon est une autre solution de capture vocale. Cette solution se concentre sur une utilisation en champ lointain, comme pour les téléviseurs, les barres de son, les décodeurs et les adaptateurs multimédias numériques. Ces applications requièrent la prise en charge de l'annulation de l'écho acoustique (AEC) stéréo pour des solutions d'interface vocale « dans toute la pièce » et permettent aux utilisateurs d'allumer leur téléviseur et de régler leurs lampes de chevet à l'aide de commandes vocales.
Dans les applications de capture vocale en champ lointain, il est essentiel que les signaux de référence AEC soient étalonnés avec précision et que la latence soit minutieusement ajustée. En procédant ainsi, les concepteurs peuvent être certains que les accessoires vocaux en champ lointain qu'ils conçoivent peuvent entendre et capturer précisément les commandes vocales de l'utilisateur quels que soient le volume du contenu et l'environnement.
Le kit VocalFusion est une solution de microphones linéaires en réseau, qu'Amazon a reconnu pour ses performances en champ lointain. Il permet aux concepteurs d'intégrer Alexa dans des dispositifs situés contre les murs des pièces, comme les téléviseurs, les systèmes d'éclairage et les appareils électroménagers intelligents. Le kit est architecturé autour du processeur vocal XVF3500-FB167-C qui offre une annulation AEC en duplex intégral à deux canaux pour prendre en charge la capture vocale dans des environnements acoustiques complexes (Figure 3). La fonctionnalité AEC compatible avec un DSP facilite la déréverbération, la commande automatique de gain et la suppression du bruit pour garantir une interaction vocale claire, même dans des environnements bruyants.
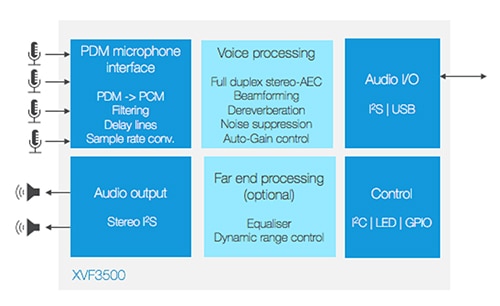 Figure 3 : Le processeur vocal XVF3500 utilise la formation de faisceaux adaptative pour localiser la source vocale souhaitée et isoler efficacement les commandes vocales provenant de sources sonores stéréo tout en supprimant le bruit de fond et les échos dans la pièce. (Source de l'image : XMOS)
Figure 3 : Le processeur vocal XVF3500 utilise la formation de faisceaux adaptative pour localiser la source vocale souhaitée et isoler efficacement les commandes vocales provenant de sources sonores stéréo tout en supprimant le bruit de fond et les échos dans la pièce. (Source de l'image : XMOS)
Ensuite, le kit VocalFusion à quatre microphones utilise les microphones MEMS IM69D130V01XTSA1 XENSIV™ d'Infineon qui fournissent des données audio brutes pour exécuter les algorithmes de traitement des signaux audio au niveau du processeur vocal XVF3500. Les microphones IM69D130 sont conçus pour permettre des performances de détection de murmures en champ lointain et offrent une distorsion harmonique totale (THD) inférieure à 1 % à des niveaux de pression acoustique (NPA) jusqu'à 128 dB.
La capacité d'intervention fournie par la conception de capture vocale permet aux utilisateurs d'interrompre un dispositif qui lit de la musique ou de le mettre sur pause, ce qui ouvre de nouvelles opportunités pour les conceptions basées sur Alexa dans les systèmes de divertissement stéréo domestiques et les équipements audiovisuels muraux (Figure 4).
") Figure 4 : Un processeur de capture vocale et un microphone fonctionnent ensemble pour créer une interface vocale pour des applications Alexa en champ lointain. (Source de l'image : Infineon Technologies)
Figure 4 : Un processeur de capture vocale et un microphone fonctionnent ensemble pour créer une interface vocale pour des applications Alexa en champ lointain. (Source de l'image : Infineon Technologies)
Le téléviseur intelligent compatible avec l'intelligence artificielle (IA) de Skyworth basé sur le processeur vocal XVF3500 est un exemple d'implémentation dans le monde réel. Le téléviseur intelligent toujours actif sort du mode veille et répond aux commandes vocales grâce à une identification de la source audio dans toutes les dimensions et à 180°, jusqu'à 5 mètres (m).
Conception de casque intelligent
Les écouteurs et les casques se situent à l'autre extrémité du spectre de conception. Lorsqu'ils sont associés aux smartphones et aux tablettes, ces dispositifs requièrent de plus en plus l'intégration d'un assistant vocal pour gérer un calendrier, contrôler des appareils domestiques intelligents, diffuser de la musique et recevoir des informations météo. Tout comme les haut-parleurs intelligents, les casques Bluetooth nécessitent une amélioration constante pour transmettre du son de qualité dans des environnements bruyants.
La conception de référence de casque intelligent et les kits de développement pour les plateformes AVS et Assistant Google de Qualcomm constituent des modules majeurs qui permettent aux développeurs de se lancer dans la conception de casques et d'appareils d'écoute qui s'activent par la voix. Les cartes de référence aident les développeurs à évaluer les assistants vocaux, tandis que les kits de conception permettent aux ingénieurs de conception de s'intéresser à l'environnement de développement complet.
Prenons l'exemple du kit de développement pour casque intelligent DK-QCC5124-GAHS-A-0 de Qualcomm pour l'Assistant Google. Il prend en charge l'activation par bouton-poussoir de l'assistant vocal de Google sur les téléphones Android sur lesquels l'application Assistant Google est installée. Il est basé sur une puce audio Bluetooth de Qualcomm qui utilise la technologie de réduction de bruit Clear Voice Capture (cVc™) de Qualcomm pour accentuer la voix d'un appelant en réduisant les bruits environnants grâce à la suppression du bruit et à d'autres améliorations audio.
La technologie cVc 6.0 permet d'occulter la perte de paquets et les erreurs sur les bits grâce à un ensemble d'algorithmes de réduction du bruit, pour profiter de conversations téléphoniques claires. Autre technologie importante qui offre de faibles latences pour une diffusion audio fiable : aptX™ HD de Qualcomm. Il s'agit d'un codec audio Bluetooth haute définition qui a été conçu pour améliorer le rapport signal/bruit et réduire les bruits de fond.
La conception de référence de casque intelligent DK-QCC5124-AVSHS-A-0 de Qualcomm pour Amazon AVS prend également en charge les technologies audio sans fil de réduction de bruit cVc 6.0 et aptX HD. Elle prend en charge l'activation d'Alexa par bouton-poussoir sur les téléphones mobiles sur lesquels l'application Alexa est installée.
La plateforme, basée sur la puce d'émetteur-récepteur Bluetooth QCC5124 de Qualcomm, prend également en charge le kit Alexa Mobile Accessory (AMA) qui permet aux utilisateurs de se connecter facilement en Bluetooth à l'application mobile Alexa sur les dispositifs Android et iOS (Figure 5). Le kit AMA facilite la communication de commandes vocales du casque vers Alexa via le téléphone, tandis qu'Amazon AVS réalise l'important travail consistant à traiter le langage naturel.
 Figure 5 : La carte de développement DK-QCC5124-AVSHS-A-0 pour Amazon AVS contient les modules essentiels d'une conception de casque intelligent. (Source de l'image : Qualcomm)
Figure 5 : La carte de développement DK-QCC5124-AVSHS-A-0 pour Amazon AVS contient les modules essentiels d'une conception de casque intelligent. (Source de l'image : Qualcomm)
Cela signifie d'abord que les développeurs n'ont pas besoin de superviser le codage pour intégrer Alexa, et qu'ils ne sont pas obligés d'ajouter du matériel de communication en plus de la connectivité Bluetooth.
À un niveau plus avancé, le kit AMA permet au service vocal Alexa d'Amazon de faciliter la communication entre des accessoires vocaux (comme un casque intelligent) et le service Alexa grâce à un mécanisme de contrôle exécuté entre l'accessoire vocal en question et l'application mobile Alexa.
Les développeurs peuvent utiliser un kit de développement à carte ouverte après l'évaluation. Cependant, la programmation du kit de développement à carte ouverte nécessite un pont de transactions (DK-TRBI200-CE684-1) qui n'est pas inclus dans le kit, mais qui peut être acheté séparément.
Conclusion
Pour les concepteurs qui souhaitent intégrer des assistants vocaux dans leurs futures conceptions, les fournisseurs de composants silicium ont déjà fait une grande partie du travail en termes de reconnaissance de mots déclencheurs, d'annulation de bruit, de fonctionnalité toujours active et de basse consommation. Grâce à leurs conceptions de référence et kits de développement, les concepteurs peuvent développer des solutions de capture vocale pour une gamme de services intelligents à commande vocale, des casques et des haut-parleurs intelligents jusqu'aux applications de domotique permettant de contrôler toute la maison grâce à la commande vocale.
Avertissement : les opinions, convictions et points de vue exprimés par les divers auteurs et/ou participants au forum sur ce site Web ne reflètent pas nécessairement ceux de DigiKey ni les politiques officielles de la société.





