

Integration von Sprachassistenten in tragbare Lautsprecher und intelligente Headsets
Zur Verfügung gestellt von Nordamerikanische Fachredakteure von DigiKey
2019-09-26
Virtuelle Assistenten wie Alexa von Amazon, Siri von Apple, Cortana von Microsoft und Google Assistant befördern die Entwicklung intelligenter sprachgesteuerter Geräte, von mit Smartphones und anderen mobilen Geräten gekoppelten Bluetooth-Headsets über intelligente Lautsprecher für Heim und Büro bis hin zu Unterhaltungselektronik wie Fernsehern. So werden sprachunterstützte Dienste zunehmend zur Steuerung von Funktionen wie beispielsweise beim Musikhören, beim Tätigen von Anrufen und Bedienen biometrischer Sensoren genutzt. Allerdings bereitet es den Entwicklern noch Schwierigkeiten, in Umgebungen, die häufig sowohl ein starkes akustisches als auch elektrisches Rauschen aufweisen, Sprache zu erkennen, zu erfassen und drahtlos zu übertragen.
Hier sind robuste Techniken zur Geräuschunterdrückung sowie eine ebenso robuste drahtlose Schnittstelle gefragt, alles zusammen in einer kompakten Lösung, mit der die Entwickler experimentieren und welche sie rasch anwenden können, um so Zeit und Geld zu sparen.
In diesem Artikel werden verschiedene Lösungen zur Spracherkennung von Cirrus Logic, XMOS und Qualcomm vorgestellt, mit denen Entwickler schnell in den Bereich sprachgesteuerte mobile Geräte und Headsets einsteigen können.
Spracherkennungslösung
Unternehmen wie Apple und Microsoft setzten ihre Lösungen anfangs mit Smartphones und Computern um, wohingegen Amazon seine Alexa mit dem intelligenten Lautsprecher Echo einführte und dann erst begann, die Funktionen von Alexa auch auf andere Geräte auszuweiten.
Allerdings arbeitet der Echo mit sieben Mikrofonen – zu viele für ein kleines Gerät im Handformat, bei dem Platz, Geld und Leistung besonders kostbar sind. Vor diesem Hintergrund bringen sich Chiphersteller wie Cirrus Logic mit einfacheren Designlösungen ins Spiel, damit Entwickler Alexa auf unterschiedliche intelligente Geräte und andere kompakte Audiosysteme übertragen können.
Als Beispiel seien hier die Anwendungen für das intelligente Heim genannt, die bei sprachgesteuerten Beleuchtungen und Haushaltsgeräten, freihändig bedienbaren, tragbaren Lautsprechern und vernetzten Lautsprechern mit Alexa Voice Service (AVS) arbeiten. In diesem Fall werden Spracherkennungslösungen zur Verbesserung der Benutzererfahrung benötigt, da sie Geräusche und andere Interferenzen unterdrücken und damit für eine genauere und zuverlässigere Sprachinteraktion sorgen.
Bei der Implementierung eines Sprachassistenten sind ein verlässlicher Start mit dem Aktivierungswort und die korrekte Interpretation von Befehlen auch in lauten Umgebungen und bei laufender Musik unerlässlich. Auch die Hallunterdrückung spielt für die Benutzerfreundlichkeit eine zentrale Rolle, da damit die Musikwiedergabe vom Benutzer angehalten und Alexa reagieren kann – auf neue Befehle kann somit korrekt geantwortet werden.
Ein guter Ausgangspunkt zum ersten Experimentieren mit AVS-Designs ist das Entwicklungskit zur Spracherkennung für AVS 598-2471-KIT von Cirrus Logic. Dieses dient der Integration der Alexa-Funktion in kompakte Audiogeräte mit akustisch abgestimmten Hardware- und Softwarekomponenten zur Audioverarbeitung (Abbildung 1). Das Kit basiert auf einer Raspberry Pi 3-Plattform und besitzt eine Referenzplatine mit dem intelligenten Codec CS47L24-CWZR von Cirrus Logic, digitale MEMS-Mikrofone und SoundClear®-Algorithmen für die Sprachsteuerung, Geräuschunterdrückung und Hallunterdrückung.
 Abbildung 1: Mit dem Entwicklungskit zur Spracherkennung 598-2471-KIT von Cirrus Logic für AVS-fähige Geräte kann eine Platine zur Spracherkennung (rechts oben) an einen Raspberry Pi 3 (links oben) entweder über Kabel angebracht oder oben auf dem Raspberry Pi 3 platziert werden. (Bildquelle: Cirrus Logic)
Abbildung 1: Mit dem Entwicklungskit zur Spracherkennung 598-2471-KIT von Cirrus Logic für AVS-fähige Geräte kann eine Platine zur Spracherkennung (rechts oben) an einen Raspberry Pi 3 (links oben) entweder über Kabel angebracht oder oben auf dem Raspberry Pi 3 platziert werden. (Bildquelle: Cirrus Logic)
Spracherkennungsbausteine
Der Spracherkennungsprozess beginnt beim Sprachprozessor CS47L24, der einen Dual-Core-300-MMAC-DSP mit einem Audio-Hub-Codec kombiniert und damit eine Vielzahl von energieeffizienten Bausteinen zur Audioverarbeitung mit festgelegten Funktionen bedienen kann (Abbildung 2). Die programmierbaren DSP-Cores unterstützen eine Reihe von modernen Audioverarbeitungsfunktionen wie die Geräuschunterdrückung bei mehreren Mikrofonen, akustische Hallunterdrückung (Acoustic Echo Cancelation, AEC) und Spracherkennung.
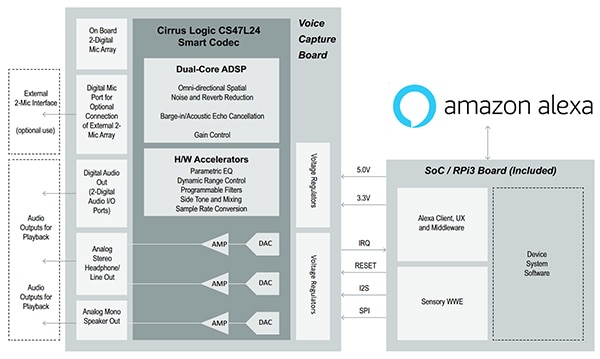 Abbildung 2: Die Spracherkennung beginnt beim Sprachprozessor CS47L24, der einen Dual-Core-300-MMAC-DSP mit einem Audio-Hub-Codec kombiniert und damit eine Vielzahl von energieeffizienten Bausteinen zur Audioverarbeitung mit festgelegten Funktionen bedienen kann. (Bildquelle: Cirrus Logic)
Abbildung 2: Die Spracherkennung beginnt beim Sprachprozessor CS47L24, der einen Dual-Core-300-MMAC-DSP mit einem Audio-Hub-Codec kombiniert und damit eine Vielzahl von energieeffizienten Bausteinen zur Audioverarbeitung mit festgelegten Funktionen bedienen kann. (Bildquelle: Cirrus Logic)
Der intelligente Codec CS47L24 nutzt einen chipintegrierten Digital/Analog-Wandler (DAW) mit einem Treiber für einen 2-Watt-Mono-Lautsprecher, um so eine High-Fidelity-Audiowiedergabe zu ermöglichen. Er unterstützt die automatische Abtastratendetektion, welche die Sprachanruf-Weitergabe im Breitband und Schmalband unterstützt. Auf dem CS47L24-Prozessor gibt es drei digitale Audioschnittstellen, die jeweils eine Reihe von standardmäßigen Audio-Abtastraten und seriellen Schnittstellenformaten unterstützen.
Der CS47L24 wird von einem externen Netzteil mit 1,8 Volt bzw. 1,2 Volt versorgt; seine Leistungs-, Takterzeugungs- und Ausgangstreiberarchitektur ist in den Modi Sprache, Musik und Standby ganz auf Energieeffizienz ausgelegt. Zudem verfügt der CS47L24 über einen eigenen MICVDD-Eingang für den Mikrofonbetrieb über 1,8 Volt.
Der Schaltkreis für die digitalen MEMS-Mikrofone und die dazugehörigen SoundClear-Algorithmen für Sprachsteuerung, Geräuschunterdrückung und Hallunterdrückung sorgt für hohe Audioqualität auf der Eingangsseite; gleichzeitig verringert er den Stromverbrauch der Mikrofone. Der Schaltkreis unterstützt zwei Betriebsmodi: den Energiesparmodus, der sich für die Erkennung von Sprachaktivitäten im Dauerbetrieb eignet, und den Hochleistungsmodus, der für High-Fidelity-Aufnahmen optimiert wurde. Bestimmt wird der Modus durch die angewandte Taktfrequenz.
Das Mikrofon verfügt über einen Analog/Digital-Wandler (ADW), um mithilfe von Kodierung mittels Pulsdichtenmodulation (PDM) einen 1-Bit-Datenstrom auszugeben und verschiedene Mikrofone in Stereo- und Array-Konfigurationen effizient miteinander zu vernetzen. Für Entwickler spielen die Schaltkreise mit mehreren Mikrofonen eine wichtige Rolle, da diese mithilfe von Beamforming-Verfahren auf die Unterdrückung besonders störender Geräusche und auf Hallunterdrückung optimiert werden können – und damit die klarste Vollduplex-Kommunikations- und Audioerfassung erzielt werden kann.
Zudem sollte das MEMS-Mikrofon einen großen dynamischen Bereich (100 Dezibel (dB) ist ein guter Ausgangspunkt) zwischen dem Grundrauschen und dem akustischen Überlastungspunkt (Acoustic Overload Point, AOP) ermöglichen. Damit werden High-Fidelity-Aufnahmen sowohl in lauten als auch in leisen Umgebungen möglich. So können beispielsweise empfindliche Audioinhalte wie klassische Musik oder Stimmen ohne Hintergrundrauschen aufgenommen werden. Gleichzeitig wird sichergestellt, dass sehr laute Audioinhalte wie Rockkonzerte und Windgeräusche keine Verzerrungen im Mikrofon hervorrufen.
Zur optimalen Nutzung der Hardware eliminieren die SoundClear-Algorithmen Geräusche über Verarbeitungsfunktionen wie Geräuschunterdrückung, Enhance™ für die automatische Spracherkennung (Automatic Speech Recognition, ASR) und Hallunterdrückung.
Fernfeld-Spracherkennung
Eine andere Spracherkennungslösung ist das Entwicklungskit VocalFusion™ stereo XK-VF3500-L33-AVS von XMOS für Amazon AVS. Dieses konzentriert sich auf Fernfeld-Einsatzszenarien wie intelligente Fernseher, Soundbars, Set-Top-Boxen und Digital Media Adapter. Solche Anwendungen bedürfen zwingend einer Stereo-AEC-Unterstützung für „raumerfassende“ Sprachschnittstellenlösungen und ermöglichen es dem Benutzer, über Sprachbefehle den Fernseher einzuschalten und die Helligkeit der Tischlampen einzustellen.
Bei Anwendungen im Bereich Fernfeld-Spracherkennung müssen die AEC-Referenzsignale genau kalibriert und die Latenz sorgfältig eingestellt werden. Damit können Entwickler sicherstellen, dass das von ihnen entwickelte Fernfeld-Spracherkennungszubehör die Sprachbefehle der Benutzer hören und akkurat erfassen kann, und das ganz unabhängig von der Lautstärke der Audioinhalte und der unmittelbaren Umgebung.
Das VocalFusion-Kit ist eine lineare Mikrofon-Array-Lösung, die von Amazon für den Einsatz im Fernfeldbereich zugelassen wurde. Mit dem Kit können Entwickler Alexa in Geräte einbauen, die sich an der Seite eines Raumes befinden, wie beispielsweise intelligente Fernseher, Lampen und Haushaltsgeräte. Das Kit baut auf dem Sprachprozessor XVF3500-FB167-C auf, der Zweikanal-Vollduplex-AEC bietet, um die Spracherkennung in komplexen akustischen Umgebungen zu unterstützen (Abbildung 3). Dank der DSP-fähigen AEC-Funktion werden Enthallung, eine automatische Verstärkungsregelung und Geräuschunterdrückung ermöglicht, um auch in lauten Umgebungen eine klare Sprachinteraktion zu gewährleisten.
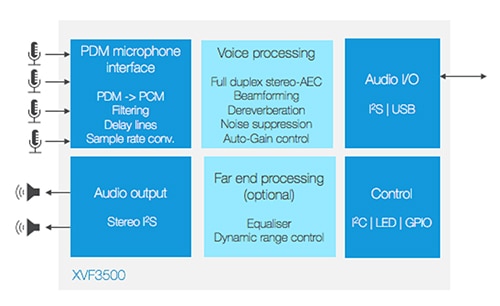 Abbildung 3: Der Sprachprozessor XVF3500 verwendet adaptives Beamforming, um die gewünschte Sprachquelle zu orten und Sprachbefehle effektiv vom Stereo-Audio zu trennen, bei gleichzeitiger Unterdrückung von Hintergrundgeräuschen und Raumechos. (Bildquelle: XMOS)
Abbildung 3: Der Sprachprozessor XVF3500 verwendet adaptives Beamforming, um die gewünschte Sprachquelle zu orten und Sprachbefehle effektiv vom Stereo-Audio zu trennen, bei gleichzeitiger Unterdrückung von Hintergrundgeräuschen und Raumechos. (Bildquelle: XMOS)
Das mit vier Mikrofonen bestückte VocalFusion-Kit arbeitet mit den MEMS-Mikrofonen XENSIV™ IM69D130V01XTSA1 von Infineon, die Audiorohdaten zum Ausführen von audiosignalverarbeitenden Algorithmen auf dem XVF3500-Sprachprozessor bereitstellen. Die Mikrofone IM69D130 sind auf die Fernfeld-Spracherkennung und Erfassung von geflüsterter Sprache ausgelegt und ermöglichen einen Gesamtklirrfaktor (THD) von unter 1 % bei Schalldruckpegeln (SPL) von bis zu 128 dB.
Mit der von der Spracherkennung bereitgestellten „Einmisch“-Funktion können Benutzer ein Gerät unterbrechen oder anhalten, das gerade Musik abspielt; damit eröffnen sich neue Möglichkeiten für Alexa-basierte Designs in der Stereo-Heimelektronik und wandmontierten AV-Geräten (Abbildung 4).
") Abbildung 4: Ein Spracherkennungsprozessor und ein Mikrofon bilden zusammen eine Sprachschnittstelle für Fernfeld-Anwendungen mit Alexa. (Bildquelle: Infineon Technologies)
Abbildung 4: Ein Spracherkennungsprozessor und ein Mikrofon bilden zusammen eine Sprachschnittstelle für Fernfeld-Anwendungen mit Alexa. (Bildquelle: Infineon Technologies)
Als Beispiel für eine echte Umsetzung sei der KI-fähige intelligente Fernseher von Skyworth genannt, der auf dem Sprachprozessor XVF3500 basiert. Der sich im Dauerbetrieb befindliche intelligente Fernseher aktiviert sich und reagiert bei Sprachbefehlen mit einer alle Richtungen umfassenden 180°-Identifizierung der Klangquelle, die bis zu 5 Meter (m) entfernt sein kann.
Intelligentes Headset-Design
Am anderen Ende des Designspektrums finden sich Ohrstöpsel und Headsets. Bei einer Kopplung mit Smartphones und Tablets machen diese zunehmend die Integration von Sprachassistenten für die Kalenderverwaltung, die Steuerung des Smart Home, das Streamen von Musik und aktualisierte Wetterberichte erforderlich. Ebenso wie intelligente Lautsprecher bedürfen auch Bluetooth-Headsets einer kontinuierlichen Verbesserung, um in lauten Umgebungen Audiosignale von hoher Qualität übertragen zu können.
Das für intelligente Headsets erstellte Referenzdesign und die dazugehörigen Entwicklungskits für AVS- und Google Assistant-Plattformen von Qualcomm stellen wichtige Bausteine dar, mit denen Entwicklern ein schneller Einstieg in den Bereich sprachaktivierte Headsets und Designs für Hearables gelingt. Mithilfe der Referenzplatinen können Entwickler die Sprachassistenten bewerten und mit den Designkits wird Konstrukteuren der Sprung in die komplette Entwicklungsumgebung ermöglicht.
Ein Beispiel hierfür ist das von Qualcomm angebotene Entwicklungskit DK-QCC5124-GAHS-A-0 für intelligente Headsets im Zusammenspiel mit dem Google Assistant. Dieses unterstützt die Aktivierung des Sprachassistenten von Google über einen Taster bei Android-Smartphones, auf denen die Google Assistant-App installiert ist. Es basiert auf einem Bluetooth-Audio-Chipset von Qualcomm, das mit der Geräuschreduzierungstechnologie Clear Voice Capture (cVc™) von Qualcomm arbeitet und so die Stimme eines Anrufers verstärkt, indem es die Umgebungsgeräusche durch Geräuschunterdrückung und andere Audio-Optimierungen verringert.
Mit der cVc 6.0-Technologie werden Paketverluste und Bitfehler über ein Set von Algorithmen zur Geräuschreduzierung kaschiert, um so für klare Telefongespräche zu sorgen. Ebenfalls bemerkenswert ist die Technologie Qualcomm aptX™ HD, die geringe Latenzen und damit ein robustes Audio-Streaming ermöglicht. Dabei handelt es sich um einen hochauflösenden Bluetooth-Audio-Codec, der zur Verbesserung des Signal-Rausch-Verhältnisses und der Verringerung der Hintergrundgeräusche entwickelt wurde.
Das von Qualcomm angebotene Referenzdesign für intelligente Headsets DK-QCC5124-AVSHS-A-0 für Amazon AVS unterstützt zudem sowohl die Geräuschreduzierung mittels cVc 6.0 als auch die drahtlosen Audiotechnologien aptX HD. Es erlaubt die Aktivierung von Alexa über einen Taster bei Smartphones, auf denen die Alexa-App installiert ist.
Zudem unterstützt die Plattform, die auf dem Bluetooth-Transceiver-Chipset QCC5124 von Qualcomm basiert, auch das Kit Alexa Mobile Accessory (AMA), mit dem Benutzer bequem eine Verbindung von Bluetooth mit der Alexa Mobile App auf Android- und iOS-Geräten herstellen können (Abbildung 5). Das AMA-Kit unterstützt die Kommunikation von Sprachbefehlen vom Headset an Alexa über das Smartphone; Amazon AVS übernimmt die Schwerarbeit bei der Verarbeitung natürlicher Sprache.
 Abbildung 5: Die Entwicklungskarte DK-QCC5124-AVSHS-A-0 für Amazon AVS enthält die zentralen Bausteine für das Design eines intelligenten Headsets. (Bildquelle: Qualcomm)
Abbildung 5: Die Entwicklungskarte DK-QCC5124-AVSHS-A-0 für Amazon AVS enthält die zentralen Bausteine für das Design eines intelligenten Headsets. (Bildquelle: Qualcomm)
Das bedeutet zweierlei: Erstens, dass Entwickler sich nicht um die umfangreiche Programmierung für ihre Alexa-Integration kümmern müssen, und zweitens, dass Entwickler von der Bluetooth-Konnektivität abgesehen keine weitere Kommunikationshardware hinzufügen müssen.
Darüber hinaus kann Amazon AVS dank dem AMA-Kit die Kommunikation zwischen dem Sprachzubehör wie einem intelligenten Headset und dem Alexa-Service über einen Steuermechanismus verbessern, der zwischen dem Sprachzubehör und der Alexa Mobile App aktiv ist.
Nach der Auswertung können die Entwickler ein Open-Board-Entwicklungskit verwenden. Allerdings ist für die Programmierung des Open-Board-Entwicklungskits eine Transaction Bridge (DK-TRBI200-CE684-1) erforderlich, welche nicht in dem Kit enthalten ist, aber separat erworben werden kann.
Fazit
Entwickler, die Sprachassistenten in ihr nächstes Design integrieren wollen, können auf die Vorarbeit der Elektronikkomponenten-Hersteller zurückgreifen, die in puncto Erkennung des Aktivierungsworts, Geräuschunterdrückung und energieeffiziente Funktionen im Dauerbetrieb bereits viel geleistet haben. Mithilfe der Referenzdesigns und Entwicklungskits der Hersteller können Entwickler nun Spracherkennungslösungen für eine Vielzahl von intelligenten Sprachsteuerungsdiensten entwickeln, von intelligenten Headsets über intelligente Lautsprecher bis hin zur vollständigen Sprachsteuerung im Heim.
Haftungsausschluss: Die Meinungen, Überzeugungen und Standpunkte der verschiedenen Autoren und/oder Forumsteilnehmer dieser Website spiegeln nicht notwendigerweise die Meinungen, Überzeugungen und Standpunkte der DigiKey oder offiziellen Politik der DigiKey wider.





