RISC-V-Multiplikationserweiterung ergänzt RV32I mit effizienter 32-Bit-Multiplikation
Die RISC-V-Befehlssatzarchitektur (instruction set architecture, ISA) wurde 2010 in Berkley in den USA geboren. RISC steht zwar für „Reduced Instruction Set Computer/Core“, aber die Hersteller können nicht widerstehen, einer RISC-ISA hier eine Anweisung oder dort einen neuen Adressierungsmodus hinzuzufügen und die Opcode-Map so lange zu füllen, bis sie mehr CISC (Complex Instruction Set Computing) als RISC ist. Aber die Entwickler von RISC-V in Berkley waren ziemlich strikt darauf bedacht, dass ihr Kern ein echter RISC ist. Der RISC-V-ISA RV32I wurde mit nur 47 Basisbefehlen (eine Zahl, die für traditionelle Star Trek-Fans eine seltsame Bedeutung hat) entworfen, und 11 Jahre später hat sie immer noch die gleiche Anzahl.
Die ursprüngliche Philosophie hinter der geringen Anzahl von Basisbefehlen ist, dass ein komplexer CISC-Befehl als eine Reihe von einfachen RISC-Befehlen reproduziert werden kann. Meiner Erfahrung nach hängt es von der jeweiligen Anwendung ab, ob dies die Code-Effizienz erhöht und die Code-Größe reduziert oder nicht. In der Vergangenheit war dies sicherlich der Fall. Das ging so weit, dass Arm die Opcode-Map um komplexe Befehle erweiterte.
Zusätzliche Befehle können zwar die Leistung verbessern, aber die Dinge werden komplizierter, wenn man einen 32-Bit-Kern mit 32-Bit-Befehlen hat und dann die Möglichkeit hinzufügen möchte, einige 32-Bit-Befehle in 16-Bit-Befehle zu komprimieren, um Platz zu sparen. Um jedoch 16-Bit-Befehle hinzuzufügen, benötigt der Kern zusätzlichen Platz in der Opcode-Map für diese komprimierten Befehle - und das Hinzufügen von CISC-Befehlen verringert die Anzahl der verfügbaren Operationscodes.
Hier kommt der Vorteil von RISC-V voll zum Tragen. Arm fügte später das komprimierte Thumb2-Befehlsformat hinzu und erweiterte die bestehende ISA um 16-Bit-Befehle durch Ergänzung einer separaten 16-Bit-ISA. Die RISC-V-ISA wurde jedoch von Anfang an mit einer Option für komprimierte Befehle entworfen und enthält daher nur eine ISA. Dadurch bleibt der Kern einfach und effizient und vereinfacht auch die Entwicklung und Prüfung von Halbleitern.
Erweiterung des RISC-V-ISA RV32I um einen Multiplikationsbefehl
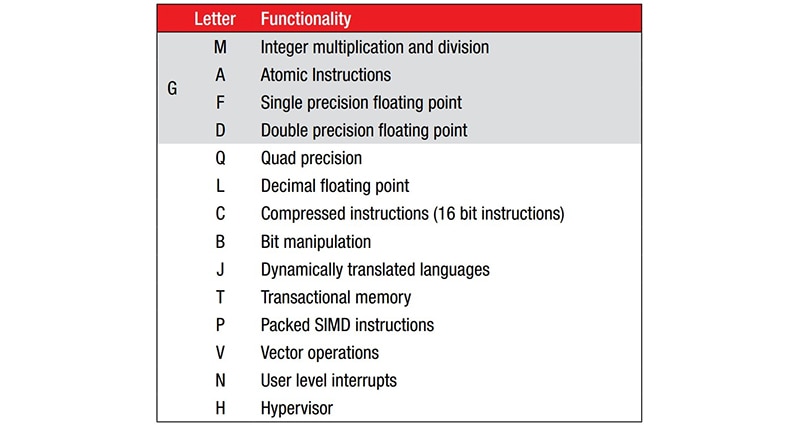
Hersteller können die ISA mit 47 Befehlen durch standardisierte Befehlserweiterungen ergänzen (Abbildung 1). Da die Grund-ISA keine Multiplikations- oder Divisionsbefehle enthält, bietet die M-Erweiterung diese Funktionalität. Eine RV32I mit der Erweiterung M würde beispielsweise als RV32IM bezeichnet werden.
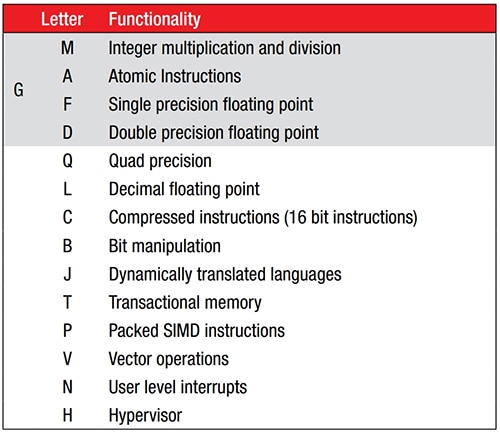 Abbildung 1: Die RISC-V-Grund-ISA mit 47 Befehlen kann durch Hinzufügen von standardisierten Befehlserweiterungen ergänzt werden, die durch einen Buchstaben hinter dem Kernnamen gekennzeichnet sind. (Bildquelle: RISC-V.org)
Abbildung 1: Die RISC-V-Grund-ISA mit 47 Befehlen kann durch Hinzufügen von standardisierten Befehlserweiterungen ergänzt werden, die durch einen Buchstaben hinter dem Kernnamen gekennzeichnet sind. (Bildquelle: RISC-V.org)
Ein Beispiel für einen Kern mit der M-Erweiterung ist der RED-V Thing Plus von SparkFun Electronics mit einem quelloffenen 32-Bit-RISC-V-Mikrocontroller Freedom E310 (FE310) mit 150 Megahertz (MHz). Der FE310-Kern wird als RV32IMAC bezeichnet. Wie aus Abbildung 1 hervorgeht, unterstützt er neben Grundrechenarten mit ganzen Zahlen (I) auch die Multiplikation ganzer Zahlen (M), atomare Befehle (A) und komprimierte Befehle (C).
Das RISC-V-Evaluierungsboard DEV-15799 RED-V (ausgesprochen „red five“) von SparkFun (Abbildung 2) verfügt über 32 Megabyte (MByte) Programmspeicher (QSPI-Flash) und hat einen USB-C-Anschluss, der eine Schnittstelle zu einem Host-Computer für Stromversorgung, Programmierung und Debugging bietet. Dazu kommt ein weiterer Steckverbinder, der für die Stromversorgung per Batterie verwendet werden kann.
 Abbildung 2: Das Board DEV-15799 von SparkFun dient zur Evaluierung des quelloffenen 150-MHz-RISC-V-Kerns FE310 RV32IMAC. Er wird über eine USB-C-Schnittstelle mit einem Host-Computer verbunden. (Bildquelle: SparkFun Electronics)
Abbildung 2: Das Board DEV-15799 von SparkFun dient zur Evaluierung des quelloffenen 150-MHz-RISC-V-Kerns FE310 RV32IMAC. Er wird über eine USB-C-Schnittstelle mit einem Host-Computer verbunden. (Bildquelle: SparkFun Electronics)
Die M-Erweiterung fügt die 32/32-Divisionsbefehle DIV und DIVU mit und ohne Vorzeichen sowie die Restwertbefehle REM und REMU mit und ohne Vorzeichen hinzu. Außerdem werden vier Multiplikationsbefehle ergänzt:
- MUL führt eine 32 x 32-Registermultiplikation durch und speichert die unteren 32 Bits des 64-Bit-Ergebnisses in einem Register.
- MULH und MULHU führen eine Registermultiplikation (mit und ohne Vorzeichen) durch und speichern die oberen 32 Bit des 64-Bit-Ergebnisses in einem Register.
- MULSHU führt eine Vorzeichen x Kein Vorzeichen-Registermultiplikation durch und speichert die oberen 32 Bits des 64-Bit-Ergebnisses in einem Register.
Für eine Multiplikation von 32 x 32 = 64 ohne Vorzeichen lautet die empfohlene Codesequenz also:
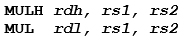
Die Register rs1 und rs2 sind der Multiplikand und der Multiplizierer und die Register rdh und rdl sind die oberen bzw. unteren 32-Bit-Ergebnisse.
Indem das 64-Bit-Multiplikationsergebnis in zwei 32-Bit-Operationen aufgeteilt wird, muss die ISA keinen komplexen CISC-Befehl 32 x 32 = 64 hinzufügen. Das steht im Einklang mit der RISC-Philosophie, einfache Befehle zur Durchführung von CISC-Operationen zu verwenden.
Während die meisten Befehle im Basis-ISA RV32I in nur einem Befehlstaktzyklus ausgeführt werden, benötigen diese Multiplikationsbefehle in der RED-V FE310 fünf. Aus diesem Grund dauert die oben empfohlene Codesequenz zehn Taktzyklen. Während das bei 150 MHz akzeptabel sein mag, habe ich schon Niederleistungs-Mikrocontroller-Anwendungen mit niedriger Taktfrequenz gesehen, bei denen Interrupts so kritisch waren, dass eine Multiplikation mit zehn Zyklen bei 5 MHz zu lang ist, um auf einen wichtigen Interrupt zu warten. In diesen Fällen habe ich beobachtet, dass Firmware-Entwickler die Multiplikation mit einer komplexen Assembler-Subroutine durchgeführt haben, die unterbrochen werden durfte.
Der FE310-Kern ist jedoch in der Lage, aufeinanderfolgende Befehle intern mittels Makro-Operationsfusion zu einem schnelleren Befehl zu verschmelzen. Die Kernmikroarchitektur kann die beiden Befehle zu einem internen Befehl verschmelzen, der schneller als in zehn Zyklen ausgeführt wird. Die RISC-V-Mikroarchitektur tut dies automatisch für einige Codesequenzen, wie z. B. indizierte Lade-, Lade-Paar- und Speicher-Paar-Befehle, was die Ausführungsgeschwindigkeit erheblich verbessert. Was noch besser ist: Da der FE310 die „C“-Erweiterung unterstützt, bei der zwei kompatible, komprimierte 16-Bit-Befehle zusammengeführt werden können, bietet er sowohl Vorteile bei der Code- als auch bei der Ausführungsgeschwindigkeit.
Während Arm die Makro-Operationsfusion erst später in seine Architekturen aufnahm, genau wie komprimierte Befehle, wurde RISC-V von Anfang an mit Makro-Operationsfusion entwickelt. Der beste Weg, die Vorteile von Code-Komprimierung und Makro-Operationsfusion tatsächlich zu verstehen und zu erkennen, ist die Beobachtung dieses Verhaltens mit einem Evaluierungsboard wie dem DEV-15799 von SparkFun. Der Code kann im Debugger untersucht werden, um zu sehen, wie die Mikroarchitektur des FE310 die einzelnen Befehle abruft und ausführt. Dadurch können Sie das Verhalten der Assemblersprache besser verstehen, was beim Schreiben von effizientem Code mit einem C-Compiler, der Codekomprimierung und Makro-Operationsfusion unterstützt, hilfreich sein kann.
Fazit
Die RISC-V-ISA wirbt stolz damit, ein wirklich reduzierter Befehlssatz mit nur 47 Basisbefehlen zu sein. Dieser kann durch standardisierte Erweiterungen wie die „M“-Multiplikationserweiterung ergänzt werden, die Multiplikations- und Divisionsbefehle hinzufügt. Die inhärente Makro-Operationsfusion der RISC-V-Architektur kann die Codeausführung kompatibler Befehle, wie z. B. aufeinanderfolgender Multiplikationsbefehle, beschleunigen, während die „C“-Erweiterung für komprimierte Befehle die Codegröße reduziert. Sowohl komprimierte Befehle als auch Makro-Operationsfusion verschaffen Ihnen erhebliche Leistungsvorteile gegenüber anderen Architekturen.
Über den Autor

Bill Giovino ist Elektronikingenieur mit einem BSEE von der Syracuse University und einer der wenigen, die erfolgreich vom Entwicklungsingenieur über den Anwendungsingenieur zum Technologiemarketing wechselten.
Seit über 25 Jahren wirbt Bill für neue Technologien vor technischem und nicht-technischem Publikum für viele Unternehmen, darunter STMicroelectronics, Intel und Maxim Integrated. Während seiner Zeit bei STMicroelectronics trug Bill dazu bei, die frühen Erfolge des Unternehmens in der Mikrocontroller-Industrie voranzutreiben. Bei Infineon inszenierte Bill die ersten Erfolge des Unternehmens im Bereich Mikrocontroller-Design in den USA. Als Marketingberater für sein Unternehmen CPU Technologies hat Bill vielen Unternehmen geholfen, unterbewertete Produkte in Erfolgsgeschichten zu verwandeln.
Bill war zudem ein früher Anwender des Internets der Dinge, einschließlich der Implementierung des ersten vollständigen TCP/IP-Stacks auf einem Mikrocontroller. Die Botschaft von „Verkauf durch Aufklärung“ und die zunehmende Bedeutung einer klaren, gut geschriebenen Kommunikation bei der Vermarktung von Produkten im Internet sind Bills Anliegen. Er ist Moderator der beliebten „Semiconductor Sales & Marketing Group“ auf LinkedIn und spricht fließend B2E.

Have questions or comments? Continue the conversation on TechForum, Digi-Key's online community and technical resource.
Visit TechForumVerwandte Blogs

Weitere Beiträge dieses Autors