

Integrazione di assistenti vocali in altoparlanti portatili e cuffie intelligenti
Contributo di Editori nordamericani di DigiKey
2019-09-26
Assistenti virtuali come Alexa di Amazon, Siri di Apple, Cortana di Microsoft e Assistente Google stanno favorendo la realizzazione di dispositivi intelligenti e a controllo vocale che vanno dalle cuffie Bluetooth abbinate a smartphone e altri dispositivi mobili ad altoparlanti intelligenti per la domotica e l'automazione d'ufficio, oltre a prodotti elettronici consumer come i televisori. Nonostante l'uso crescente di servizi a controllo vocale per gestire funzioni come l'ascolto di musica, le chiamate e l'attivazione di sensori biometrici, i progettisti hanno difficoltà a identificare, acquisire e trasmettere la voce in modo wireless in ambienti spesso rumorosi sia acusticamente che elettricamente.
Servono solide tecniche di cancellazione del rumore e un'interfaccia wireless altrettanto robusta, integrate in un pacchetto che gli sviluppatori possono sperimentare e applicare rapidamente per risparmiare tempo e costi.
Questo articolo presenta diverse soluzioni di acquisizione vocale di Cirrus Logic, XMOS e Qualcomm che aiutano i progettisti a progettare rapidamente dispositivi mobili e cuffie di ultima generazione a controllo vocale.
Soluzione di acquisizione vocale
Aziende come Apple e Microsoft hanno iniziato a implementare le loro soluzioni in smartphone e computer, mentre Amazon ha lanciato Alexa con l'altoparlante intelligente Echo e ha poi iniziato a espanderne l'impiego in altri dispositivi.
Tuttavia, Echo ha sette microfoni, troppi per un piccolo dispositivo portatile dove lo spazio, il costo e il consumo energetico rivestono un'importanza cruciale. Detto questo, produttori di chip come Cirrus Logic si stanno dedicando attivamente a trovare soluzioni progettualmente più semplici per permettere ai progettisti di introdurre Alexa in diversi dispositivi intelligenti e in altri fattori di forma del sistema audio.
Si prendano, ad esempio, le applicazioni di domotica che utilizzano Alexa Voice Service (AVS) in apparecchi di illuminazione a controllo vocale, altoparlanti portatili vivavoce e altoparlanti in rete. In questo caso, per migliorare l'esperienza dell'utente servono soluzioni di acquisizione vocale che sopprimano il rumore e altre interferenze del mondo reale per permettere interazioni vocali più accurate e affidabili.
L'implementazione di un assistente vocale richiede l'attivazione di parole di "risveglio" ad alta precisione e l'interpretazione dei comandi in ambienti rumorosi e durante la riproduzione di musica. Per offrire all'utente un'esperienza di alta qualità è inoltre fondamentale cancellare l'eco; l'utente potrà così interrompere la riproduzione di musica ad alto volume e le risposte di Alexa per facilitare risposte accurate a nuove richieste.
Un buon punto di partenza per iniziare la sperimentazione con i progetti AVS è quello di lavorare con il kit di sviluppo per l'acquisizione vocale per AVS 598-2471-KIT di Cirrus Logic. L'obiettivo è quello di integrare la capacità di Alexa in dispositivi audio compatti con componenti hardware e software di elaborazione audio sintonizzati acusticamente (Figura 1). Il kit si basa su una piattaforma Raspberry Pi 3 e include una scheda di riferimento che offre il codec intelligente CS47L24-CWZR di Cirrus Logic, microfoni MEMS digitali e algoritmi SoundClear® per il controllo vocale, la soppressione del rumore e la cancellazione dell'eco.
 Figura 1: Il kit di sviluppo per l'acquisizione vocale 598-2471-KIT di Cirrus Logic per dispositivi abilitati AVS consente di collegare una scheda di acquisizione vocale (in alto a destra) a un Raspberry Pi 3 (in alto a sinistra) via cavo o posizionandola come un HAT sopra al Raspberry Pi 3. (Immagine per gentile concessione di Cirrus Logic)
Figura 1: Il kit di sviluppo per l'acquisizione vocale 598-2471-KIT di Cirrus Logic per dispositivi abilitati AVS consente di collegare una scheda di acquisizione vocale (in alto a destra) a un Raspberry Pi 3 (in alto a sinistra) via cavo o posizionandola come un HAT sopra al Raspberry Pi 3. (Immagine per gentile concessione di Cirrus Logic)
Componenti costitutivi per l'acquisizione vocale
Il processo di acquisizione vocale inizia con il processore vocale CS47L24 che abbina un DSP 300 MMAC dual-core a un codec hub audio per servire una serie di blocchi di elaborazione audio a funzione fissa e ad alta efficienza energetica (Figura 2). I core DSP programmabili supportano diverse funzioni avanzate di elaborazione audio come la soppressione del rumore multimicrofono, la cancellazione dell'eco acustica (AEC) e il riconoscimento vocale.
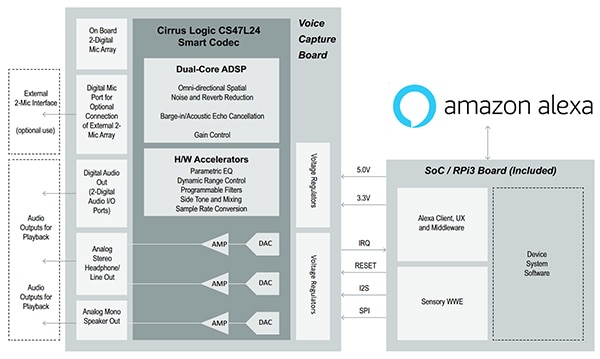 Figura 2: L'acquisizione vocale sul kit inizia con il processore vocale CS47L24 che abbina un DSP 300 MMAC dual-core a un codec hub audio per servire diversi blocchi di elaborazione audio a funzione fissa ed energeticamente efficienti. (Immagine per gentile concessione di Cirrus Logic)
Figura 2: L'acquisizione vocale sul kit inizia con il processore vocale CS47L24 che abbina un DSP 300 MMAC dual-core a un codec hub audio per servire diversi blocchi di elaborazione audio a funzione fissa ed energeticamente efficienti. (Immagine per gentile concessione di Cirrus Logic)
Il codec intelligente CS47L24 utilizza un convertitore digitale/analogico (DAC) su chip con driver per altoparlanti mono da 2 W per consentire una riproduzione audio ad alta fedeltà. Supporta il rilevamento automatico della frequenza di campionamento che facilita la trasmissione delle chiamate vocali a banda larga e stretta. Il processore CS47L24 è dotato di tre interfacce audio digitali, ognuna delle quali supporta un intervallo di frequenze di campionamento audio standard e formati di interfaccia seriale.
CS47L24 è alimentato da alimentatori esterni a 1,8 V e 1,2 V. Le sue architetture di alimentazione, clocking e driver di uscita sono tutte progettate per assicurare bassi consumi in modalità voce, musica e standby. CS47L24 fornisce anche un ingresso MICVDD separato per il funzionamento del microfono oltre 1,8 V.
Il circuito integrato dei microfoni digitali MEMS e i relativi algoritmi SoundClear per il controllo della voce, la soppressione del rumore e la cancellazione dell'eco assicurano un audio di alta qualità in ingresso, riducendo al contempo il consumo energetico del microfono. Il circuito integrato supporta due modalità operative: la modalità a basso consumo energetico, adatta per il rilevamento continuo dell'attività vocale, e la modalità ad alte prestazioni, ottimizzata per la registrazione ad alta fedeltà. La modalità dipende dalla frequenza di clock applicata.
Il microfono incorpora un convertitore analogico/digitale (ADC) per inviare un flusso di dati a un bit utilizzando la codifica PDM (modulazione di densità di impulso) e per collegare in modo efficiente più microfoni in configurazioni stereo e array. È importante che i progettisti cerchino circuiti integrati per più microfoni, perché possono essere ottimizzati per assicurare una forte riduzione del rumore e la cancellazione dell'eco utilizzando tecniche di formazione del fascio per ottenere la comunicazione full-duplex e l'acquisizione audio più chiare.
Il microfono MEMS dovrebbe inoltre facilitare un'ampia gamma dinamica (100 dB è un buon punto di partenza) tra il rumore di fondo e il punto di sovraccarico acustico. Ciò consente la registrazione audio ad alta fedeltà in ambienti sia silenziosi che rumorosi. Permette ad esempio di registrare contenuti audio di basso livello come la musica classica o la voce, senza fischi di sottofondo. Allo stesso tempo, assicura che suoni molto forti come quelli dei concerti rock e il rumore del vento non causino distorsioni nel microfono.
Per sfruttare al meglio l'hardware, gli algoritmi SoundClear eliminano il rumore attraverso funzioni di elaborazione come la soppressione del rumore, il riconoscimento vocale automatico (ASR) Enhance™ e la cancellazione dell'eco.
Acquisizione vocale far-field
Un'altra soluzione di acquisizione vocale è rappresentata dal kit di sviluppo stereo VocalFusion™ XK-VF3500-L33-AVS di XMOS per Amazon AVS. Il kit è dedicato a casi d'uso far-field come smart TV, soundbar, set-top box e adattatori multimediali digitali. Queste applicazioni richiedono il supporto AEC stereo per soluzioni di interfaccia vocale "across the room" e consentono agli utenti di accendere la TV e regolare le lampade da tavolo tramite comandi vocali.
Le applicazioni di acquisizione vocale far-field richiedono la calibrazione accurata dei segnali di riferimento AEC e l'attenta regolazione della latenza. I progettisti possono così avere la certezza che gli accessori vocali far-field che progettano riescono a sentire e ad acquisire accuratamente i comandi vocali dell'utente, a prescindere dal volume dei contenuti e dall'ambiente circostante.
Il kit VocalFusion è una soluzione che comprende un array di microfoni lineari qualificata da Amazon per le prestazioni far-field. Permette ai progettisti di inserire Alexa in dispositivi ai margini della stanza come smart TV, illuminazione ed elettrodomestici. Il kit si basa sul processore vocale XVF3500-FB167-C che fornisce un AEC full-duplex a due canali a supporto dell'acquisizione vocale in ambienti acusticamente complessi (Figura 3). La capacità AEC abilitata per DSP facilita l'eliminazione del riverbero, il controllo automatico del guadagno e la soppressione del rumore per garantire un'interazione vocale nitida anche in ambienti rumorosi.
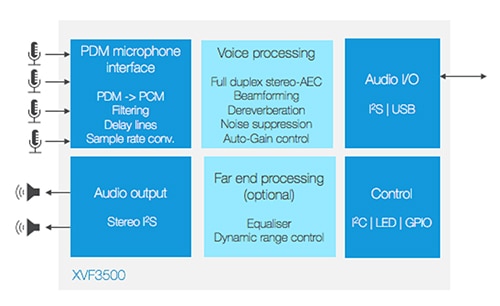 Figura 3: Il processore vocale XVF3500 si serve di un beamforming adattivo per localizzare la fonte desiderata della voce e isolare in modo efficace i comandi vocali dall'audio stereo, sopprimendo al contempo il rumore di fondo e gli echi della stanza. (Immagine per gentile concessione di XMOS)
Figura 3: Il processore vocale XVF3500 si serve di un beamforming adattivo per localizzare la fonte desiderata della voce e isolare in modo efficace i comandi vocali dall'audio stereo, sopprimendo al contempo il rumore di fondo e gli echi della stanza. (Immagine per gentile concessione di XMOS)
Il kit di quattro microfoni VocalFusion utilizza i microfoni MEMS IM69D130V01XTSA1 XENSIV™ di Infineon che forniscono dati audio grezzi per eseguire algoritmi di elaborazione dei segnali audio sul processore vocale XVF3500. I microfoni IM69D130 sono progettati per rilevare voci lontane e sussurrate e per una distorsione armonica totale (THD) inferiore all'1% a livelli di pressione sonora (SPL) fino a 128 dB.
La capacità di "intromissione" fornita dalla progettazione dell'acquisizione vocale consente agli utenti di interrompere o mettere in pausa un dispositivo che sta riproducendo musica, dischiudendo nuove opportunità per i progetti basati su Alexa nel campo dell'home entertainment stereo e delle apparecchiature AV a parete (Figura 4).
") Figura 4: Interazione tra un processore di acquisizione vocale e un microfono per realizzare un'interfaccia vocale per applicazioni Alexa far-field. (Immagine per gentile concessione di Infineon Technologies)
Figura 4: Interazione tra un processore di acquisizione vocale e un microfono per realizzare un'interfaccia vocale per applicazioni Alexa far-field. (Immagine per gentile concessione di Infineon Technologies)
Un esempio di implementazione nel mondo reale è quello della smart TV abilitata per l'intelligenza artificiale (IA) di Skyworth, basata sul processore vocale XVF3500. La smart TV sempre accesa si risveglia e risponde ai comandi vocali con identificazione della fonte del suono a 180° all-dimensional da un massimo di 5 metri.
Design intelligente delle cuffie
All'altro capo dello spettro di progettazione vi sono gli earbud e le cuffie. Abbinati a smartphone e tablet, richiedono sempre più spesso l'integrazione di un assistente vocale per la gestione del calendario, il controllo della domotica, la musica in streaming e gli aggiornamenti meteo. Analogamente agli altoparlanti intelligenti, anche le cuffie Bluetooth richiedono continui miglioramenti per trasmettere audio di qualità in ambienti rumorosi.
I kit di sviluppo e progettazione di riferimento di cuffie intelligenti di Qualcomm per le piattaforme AVS e Assistente Google sono gli strumenti principali che consentono agli sviluppatori di iniziare a progettare cuffie e intrauricolari intelligenti ad attivazione vocale. Le schede di riferimento aiutano a valutare gli assistenti vocali, mentre i kit di progettazione consentono ai progettisti di passare all'ambiente di sviluppo completo.
Si prenda ad esempio il kit di sviluppo per cuffie intelligenti DK-QCC5124-GAHS-A-0 di Qualcomm per l'Assistente Google. Supporta l'attivazione dei pulsanti per l'assistente vocale di Google sui telefoni Android su cui è installata l'applicazione Assistente Google. Si basa su un chipset audio Bluetooth di Qualcomm che utilizza la tecnologia di riduzione del rumore Qualcomm Clear Voice Capture (cVc™) per migliorare la voce del chiamante riducendo i suoni ambientali attraverso la soppressione del rumore e altri miglioramenti audio.
La tecnologia cVc 6.0 fornisce l'occultamento della perdita di pacchetti e degli errori di bit attraverso una serie di algoritmi di riduzione del rumore per conversazioni telefoniche chiare. Un'altra tecnologia degna di nota è aptX™ HD di Qualcomm che facilita le basse latenze per uno streaming audio affidabile. Si tratta di un codec audio Bluetooth ad alta definizione studiato per migliorare il rapporto segnale/rumore e ridurre il rumore di fondo.
Il progetto di riferimento per cuffie intelligenti DK-QCC5124-AVSHS-A-0 di Qualcomm per Amazon AVS supporta anche sia la tecnologia di riduzione del rumore cVc 6.0 che quella audio wireless aptX HD. Supporta inoltre l'attivazione dei pulsanti per Alexa sui telefoni cellulari su cui è installata l'app Alexa.
La piattaforma, realizzata sul chipset del ricetrasmettitore Bluetooth QCC5124 di Qualcomm, supporta anche il kit Alexa Mobile Accessory (AMA) che permette agli utenti di collegare comodamente Bluetooth con l'app Alexa Mobile su dispositivi Android e iOS (Figura 5). Il kit AMA facilita la comunicazione dei comandi vocali dalla cuffia ad Alexa via telefono, mentre il lavoro pesante di elaborazione del linguaggio naturale è svolto da Amazon AVS.
 Figura 5: La scheda di sviluppo DK-QCC5124-AVSHS-A-0 per Amazon AVS comprende i componenti costitutivi di un progetto di cuffie intelligenti. (Immagine per gentile concessione di Qualcomm)
Figura 5: La scheda di sviluppo DK-QCC5124-AVSHS-A-0 per Amazon AVS comprende i componenti costitutivi di un progetto di cuffie intelligenti. (Immagine per gentile concessione di Qualcomm)
Questo implica due cose: innanzitutto, gli sviluppatori non hanno bisogno di controllare la corposa codifica per l'integrazione di Alexa e in secondo luogo non devono aggiungere nessun hardware di comunicazione oltre alla connettività Bluetooth.
A un livello superiore, il kit AMA permette ad Amazon AVS di facilitare la comunicazione fra accessori vocali come una cuffia intelligente e il servizio Alexa attraverso un meccanismo di controllo che opera tra l'accessorio vocale e l'app Alexa Mobile.
Gli sviluppatori possono utilizzare un kit di sviluppo open board dopo la valutazione. Tuttavia, la programmazione del kit di sviluppo open board richiede un Transaction Bridge (DK-TRBI200-CE684-1) non incluso nel kit ma acquistabile separatamente.
Conclusione
Per i progettisti che desiderano integrare gli assistenti vocali nel loro prossimo progetto, i fornitori di chip hanno già fatto gran parte del lavoro più gravoso in termini di riconoscimento delle parole di risveglio, cancellazione del rumore e funzionalità sempre attiva a basso consumo energetico. Utilizzando i loro progetti di riferimento e i loro kit di sviluppo, i progettisti possono sviluppare soluzioni di acquisizione vocale per numerosi servizi di controllo vocale intelligente, dalle cuffie e dagli altoparlanti intelligenti al controllo vocale domestico completo.
Esonero della responsabilità: le opinioni, le convinzioni e i punti di vista espressi dai vari autori e/o dai partecipanti al forum su questo sito Web non riflettono necessariamente le opinioni, le convinzioni e i punti di vista di DigiKey o le sue politiche.





